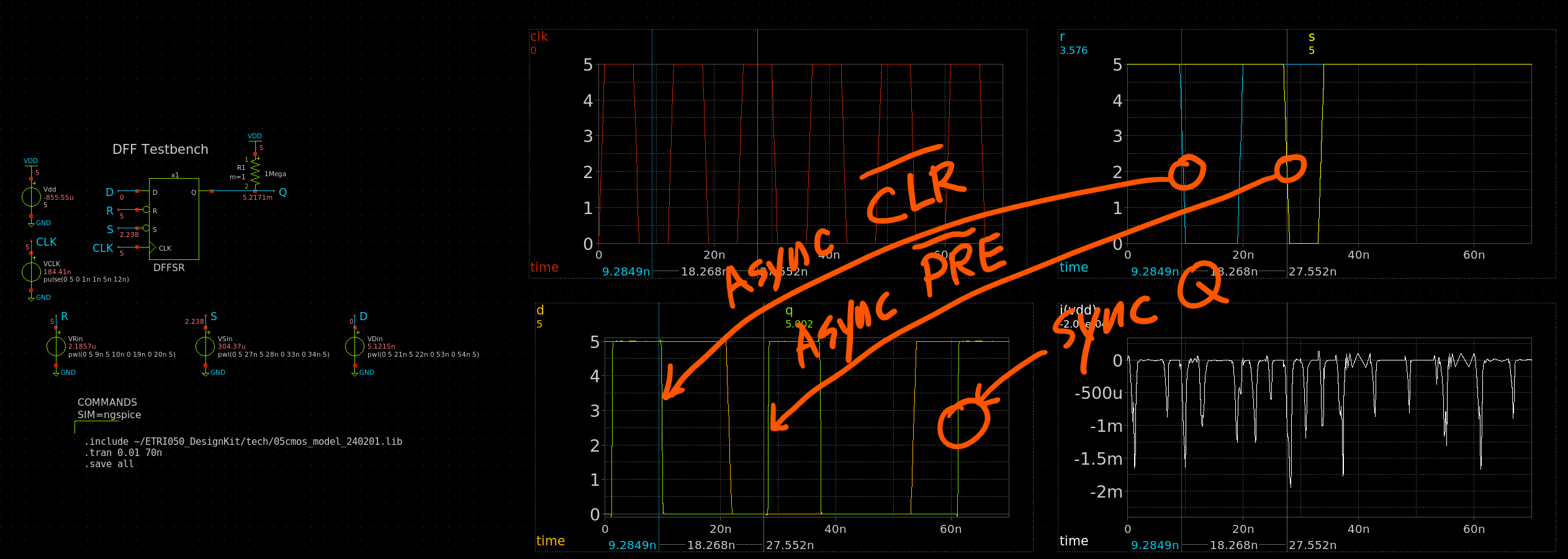
"Verilog-Verilator-SystemC 방법론 기초"
[2] 설계 언어 Verilog 와 검증 언어 SystemC
[알림] 아래 내용중 질문, 지적, 보강 등 어떤 사항도 환영 합니다.
"Verilog-Verilator-SystemC 방법론 기초"는 "내 칩(My Chip) MPW 서비스": 오픈-소스 도구 활용 반도체 설계 특별과정 중 두번째 강좌로서 베릴로그(Verilog)와 오픈-소스 시뮬레이션 도구 Verilator 그리고 시스템 수준 검증 방법론 SystemC의 입문 과정이다. 컴퓨팅 언어를 활용한 디지털 회로의 설계와 검증을 다룬다(Quantative approach to digital circuit design using computing language and Open-Source EDA tools).
강의 내용은 아래와 같다.
[1] 도구 설치 [링크]
[2] 설계 언어 Verilog 와 검증 언어 SystemC/C++[링크]
[3] 하드웨어 기술 언어의 코딩 스타일[링크]
[4] 실습: 쉬프트 레지스터 [링크]
[5] 실습: FIR 필터 [링크]
[6] "내 칩 MPW" 요건에 맞춘 FIR 필터의 PE 설계[링크]
[부록] FIR 필터 PE의 "내 칩MPW" 제출용 GDS 생성[링크]
------------------------------------------------------
목차
I. 설계의 언어와 검증의 언어
II. 설계 언어 Verilog
II-1. 플립-플롭을 언어로 묘사하기
II-2. 프로그래밍 언어로 표현하는 논리식과 논리회로
II-3. 하드웨어 기술 언어의 최소 요건
a. 순차 구문
b. 병렬구문
c. 하드웨어 객체
d. 두가지 할당 연산자
III. 검증 언어 SystemC/C++
III-1. C++ 크래스 이해의 최소선
III-2. SystemC에 대한 다른 견해
IV. 맺음말
--------------------------------------------------------
I. 설계의 언어와 검증의 언어
설계 방법의 추상성(abstraction level)을 높이는 목적은 생산성을 위해서다. 짧은 시간에 적은 인력으로 더 큰 규모의 설계를 완성하려는 것이다. 인간의 언어에 가까우면서 자동 번역이 가능한 형식을 갖춘 컴퓨팅 언어를 도입하므로써 높은 설계 생산성을 이뤘다. 소프트웨어의 개발 뿐만 아니라 하드웨어 설계에도 높은 추상화 수준을 갖춘 컴퓨팅 언어의 사용이 자리잡았다.
디지털 전자회로의 동작은 논리식(logical expression)으로 표현 할 수 있다. 컴퓨팅 언어로 묘사된 높은 추상화 수준의 행위(알고리즘)는 전자회로로 자동변환이 가능하다. Verilog(베릴로그)는 하드웨어의 행위를 묘사하기 위해 채택된 컴퓨팅 언어다.

하드웨어 기술 언어 HDL(Hardware Description Language)의 최종 목표는 전자회로의 제조를 위한 도면의 생성이다. 큰 비용이 드는 전자회로 반도체는 제작 이전에 충분히 검토되어야 한다. 제조도면의 생성을 목표로 하는 하드웨어 행위의 묘사를 설계(design)라 한다면 검증(verification)은 이 하드웨어가 목적하는 사양서(specification) 대로 기능하는지 확인하는 절차다.
설계와 검증은 동일한 언어(방법론)를 사용하는 것이 보통이었다. 설계 규모가 증가하고 내용이 복잡해 지면서 높은 추상화 수준의 검증 방법론이 필요해졌고 기존의 언어를 차용한 HVL (hardware verification language)이 등장 했다. 현재 사용되고 있는 HVL로 SystemVerilog, OpenVera, e, SystemC 들이 있으며 HDL과 더블어 표준으로 등재되었다[1]. 이들은 프로그래밍 언어에 임의 비트(bit manipulation)와 사건처리(event process)등 하드웨어 객체 표현 방법과 시스템 모델링의 요건으로 병렬실행 구문(concurrent execution statement)을 추가하였다. 그에 덧붙여 공유 객체(SO, shared object), 동적 라이브러리(DLL, dynamic linking library)는 물론 프로세스간 통신(IPC, inter-process communication) 기법을 활용하여 다른 방법론에서 축적된 자원을 재활용 하거나 이종 언어를 통합하기도 한다.
Verilog 언어는 하드웨어의 기술을 목적으로 발명된 언어다. 테스트벤치의 작성을 위해 추상성을 높이며 발전되었다. Verilog로도 시스템 수준 테스트벤치의 작성이 가능하지만 C++에 비하면 엄청난 수고가 든다.
SystemC는 새로운 언어가 아니다. 하드웨어 객체를 표현 할 수 있는 C++의 크래스로서 병렬실행 시뮬레이터를 라이브러리로 제공한다. SystemC로 작성된 모델은 C++ 컴파일러로 실행 파일을 생성한다.
이번 학습은 Verilog로 레지스터 트랜스퍼 수준(RTL, Register-Trasfer Level)에서 디지털 논리회로를 기술하고 SystemC로 테스트벤치를 작성하여 검증하는 방법론을 소개한다. Verilog와 SystemC가 담고 있는 방대한 내용을 단숨에 배우기는 불가능하다. 전자 설계 자동화 도구(EDA Tools)를 활용한 반도체 설계의 필요 최소한 내용을 학습한다.
II. 설계 언어 Verilog
컴퓨팅 언어를 단숨에 배워보자는 동영상이 넘친다. 그러면서 몇시간짜리 동영상을 내밀곤 한다. 다보기 전에 지친다. 체계적인 학습이라 하면서 수백 페이지 교과서를 가지고 몇달을 보낸다. 그러다 지친다. 몇번을 시도하다 결국 처음 몇장 만 훤하다. "체계적 학습"이라는 교실에서 나와 길 위에서 배워보자.
II-1. 플립-플롭을 언어로 묘사하기
논리회로는 이미 배워 알고 있다. 굳이 Verilog 라는 언어를 쓰지 않고 디지털 회로를 표현 할 수 있을지 스스로 질문해 보자. 예를 들어 D 플립 플롭(D-FlipFlop)을 일상 언어로 기술해보자. 그리고 C 언어로 옮겨보자. 언어로 표현하기 곤란 하면 그림은 어떤가?

언어로 디지털 회로를 설계하려고 나선 참인데, 왜? 말로는 어려웠을까? 적당한 용어(jargon)를 찾기 어려웠을 지도 모른다. 다시 D 플립플롭의 '동작'(또는 '행동' 또는 '행위')을 말로 표현해보자.
"클럭으로 지정된 입력 CLK 에 상승 엣지(positive edge)가 감지되면 입력 D 를 Q에 전송한다. 그 이외의 경우 Q는 변화 없다(또는 이전 값을 유지한다)."
위의 문장에서 등장하는 '클럭', '엣지', '전송', '변화' 라는 단어의 이해는 논리회로를 배우기 이전과 이후로 갈린다. 이에 더하여 '이전'이라는 표현이 시간의 흐름을 내포하고 있다. 이번에는 C 언어로 표현해보자.
if (CLK==1)
Q = D;
이 문장이 D 플립 플롭을 제대로 표현하고 있을까? 플립플롭의 가장 중요한 동작 요인인 '엣지'의 표현이 없다.
II-2. 프로그래밍 언어로 표현하는 논리식과 논리회로
이번에는 논리식(logical expression)이다. 아래와 같은 간단한 논리회로가 있다.

논리식은 어떤 컴퓨팅 언어로도 쉽게 표현 할 수 있다.
X = B & A;
D = X | C;
C 언어라면 위의 두 문장의 순서를 바꿔도 좋을까? SPICE 네트리스트를 떠올려보자. 전자회로를 기술하는 경우라면 두 문장의 순서를 바꿔도 좋다.
II-3. 하드웨어 기술 언어의 최소 요건
위의 간단한 두가지 예를 보더라도 프로그래밍 언어 C 로 하드웨어를 묘사하기 곤란하겠다는 짐작이 간다. 그래서 하드웨어 기술 언어 HDL이 제안되었다.
a. 순차 구문
하드웨어 기술 언어 Verilog는 플립-플롭을 어떻게 기술하는지 보자.
always @(posedge CLK)
begin
Q <= D;
end
always @()는 소괄호 안에 나열된 신호의 조건이 맞으면 그 아래 딸린 구문을들 실행한다는 뜻이다. 소괄호 안에 나열된 신호들을 감응 신호들(sensitivity list)이라고 한다. 괄호안의 posedge는 신호의 상태를 평가해주는 연산자다. clk가 상승 엣지인지 평가하여 참일 경우 D의 값을 Q 로 전송한다는 의미라는 것은 쉽게 짐작할 수 있다. 그리고 그 짐작이 맞다. 만일 평가 조건이 맞지 않으면(CLK가 0 또는 1 을 유지하고 있을 때는 물론 하강 엣지일 때)는 전송은 실행되지 않게 되므로 Q 는 이전 값을 계속 유지한다. D 플립 플롭의 전형적인 묘사다. 굳이 영어 단어 'always'의 뜻을 적용하여 표현 하면 이렇다.
"소괄호 안에 나열된 신호를 평가하여 참(true)일 때 항상 아래에 딸린 구문들을 순차적으로 실행 한다"
always 구역 내의 구문들은 모두 순차적인 행위를 묘사한다는 점에 유의한다.
b. 병렬구문
산술 연산과 논리 연산은 모두 C 언어의 그것과 같은 표현 방식을 따른다. 다만 하드웨어 언어의 모든 문장은 병렬실행(concurrent statement)으로 문장이 놓인 순서는 실행 결과에 영향을 주지 않는다. 병렬 할당문을 명시하기 위해 assign 키 워드(key word)로 명시한다. 위의 조합회로 예를 Verilog 병렬 할당 문으로 표현하면 다음과 같다.
assign X = B & A;
assign D = X | C;
병렬 할당문에서 할당 대상은 중복(multiple drive)될 수 없다.
assign X = B & A;
assign D = X | C;
assign X = E ^ F;
하드웨어를 기술한다는 점을 감안하면 전기적인 충돌을 허용할 수 없으므로 이의 금지는 당연하다. 컴퓨팅 언어를 사용한 알고리즘의 기술에 문법적 오류는 당연하며 논리적 오류가 없어야 함은 물론이다. 하드웨어 언어를 사용할 때는 이에 더하여 전기전자 회로의 위반(violation)이 없어야 한다.

c. 하드웨어 객체
하드웨어 언어에서 객체는 기본적으로 1비트 전선(net)이다. 단 병렬 할당과 순차 할당을 구별해 선언 한다.
reg x;
wire x;
다수의 비트를 가진 객체를 선언하기 위해 대괄호를 사용한다.
wire [7:0] z;
객체 z 는 8비트 폭의 전선으로 상위 비트의 위치가 [7]이다. 레지스터 reg 로 선언 되었다고 해서 반드시 디지털 회로의 D 플립플롭을 의미하는 것은 아니다. 기술된 행위에 따라 디지털 데이터의 저장용 플립플롭으로 해석된다. 아래와 같은 기술은 비록 c 가 reg 로 선언 되었어도 조합회로 멀티플렉서(multi-plexer)다.
always @(s, a, b)
begin
if (s)
c <= a;
else
c <= b;
end
감응으로 지정한 신호 s, a, b에 상승(0->1)과 하강(1->0)의 구분 없이 사건(event, 변화)가 발생하면 if ~ else 문이 실행된다. s의 모든 경우에 할당이 이뤄지고 있다. 이에 반해 아래의 예에서 s 가 0일 경우 할당 문이 없다. 즉, s 가 0 일때 c 는 이전 값을 유지하고 있으라는 의미다. 디지털 회로의 래치(latch)를 묘사한 것이다.
always @(s, a)
begin
if (s)
c <= a;
end
always 구역 내의 할당은 reg로 선언되어야 한다. 순차실행 할당 연산자는 <= 다.
d. 두가지 할당 연산자
Verilog는 C 언어를 많이 닮았다고 한다. 따로 설명 할 것도 없이 C 언어의 연산자와 동일하다. 다만 할당 연산자(assignment operator)의 경우 순차구문의 연산자 <= 와 병렬구문의 연산자 = 를 별도로 두고 있다. 각각 즉시할당(immediate assign)과 지연할당(deferred assign)이라고 한다.
순차구문에서 할당은 프로그래밍 언어의 할당과 같은 방식으로 일어난다. 할당 연산자 <= 의 오른편 rhs(right hand side)의 수식이 평가되어 즉시 왼편 lhs로 전송된다.
병렬구문에서 할당은 오른편의 수식의 평가, 이전 값과 비교 후 사건고지, 시뮬레이터에 의한 일률 갱신으로 할당이 이뤄진다.
두 할당으로 구분하는 이유는 시뮬레이션 소프트웨어로 병렬 구문을 모의실행하기 위한 방법이다. 아래 그림은 SystemC 1.x 의 시뮬레이터네서 병렬 구문의 할당과 사건처리 후 갱신을 설명하는 개념도다.

"내 칩 MPW" 지원에 당면하여 알아야할 Verilog는 최소한을 살펴봤다. Verilog는 C 언어를 많이 닮았다며 쉽게 시작 했다가 병렬성에 이르러 곤란을 격는다. 하드웨어를 다룬다는 점을 염두에 두고 상식으로 생각하면 이해되지 않을 것은 없다.
III. 검증 언어 SystemC/C++
검증은 설계물이 목표한 동작을 하는지 확인하는 절차다. 설계 언어는 레지스터 트랜스퍼 수준 RTL에서 디지털 논리회로를 기술한다. 순서에 따라 입력을 주고 출력을 검사하는 검증 환경(테스트벤치, testbench)의 구축에 RTL은 매우 불리하다. 알고리즘을 기술하는 컴퓨팅 언어로 가장 탁월한 C++를 사용하기로 한다. 엄청나게 쌓인 자원(라이브러리)들은 물론 현존하는 컴퓨터와 운영체제를 반도체 설계 검증에 즉시 활용할 수 있다.
RTL에서 기술된 하드웨어를 검증 하기 위해 C++ 언어를 활용 하려면 부족한 부분을 채워야한다. 객체들은 비트 단위로 선언할 수 있어야 하며 입출력의 방향이 지정되어야 한다. 사건에 의해 구동되는 병렬실행을 모의 할 수 있어야 한다. SystemC 는 C++로 하드웨어를 모의할 수 있도록의 크래스와 템플릿 라이브러리를 제공한다.
C 를 배웠다 하더라도 C++를 받아들이기 쉽지 않다. 하물며 그 확장인 SystemC를 단숨에 익히기는 더욱 어렵다. 반도체 설계를 위해 Verilog를 배우려고 디지털 논리 회로의 이해를 기반으로 접근 했었다. SystemC를 배우기 전에 C 프로그래밍 언어를 배운 이유를 상기하기 바란다. Verilog 뿐만 아니라 그 확장 판인 SystemVerilog에서도 C/C++의 함수를 연계시키기 위한 표준이 마련되어 있다. 하드웨어 언어에서 그토록 C/C++를 들여오려고 애쓰는 까닭이 있을 것이다. Verilog 로 테스트 벤치를 작성할 수 있지만 C/C++를 활용하면 매우 수월하기 때문이다.
III-1. C++ 크래스 이해의 최소선
C와 C++의 가장 두드러진 차이를 든다면 단연 크래스와 템플릿이다. C++의 크래스(class)는 C의 구조체(struct)의 확장이다. 구조체는 복합 객체들을 담는 용기(container)다. 크레스는 객체뿐만 아니라 객체를 다루는 방법도 함께 담을 수 있다. 이 방법을 소속함수(member function)라고 한다. 템플릿은 크래스의 자료형을 유연하게 정의한다.
C++의 크래스는 매우 방대하고 추상적 개념들이 가득하다. 그 개념들이 필요한 이유를 모르고 이해하려면 고단해진다. 크래스와 템플릿의 기초만 알고 시작하자. 가장 기초적인 예제는 아래와 같다. 반도체 설계의 검증에 SystemC를 활용하기 위한 C++ 이해의 최소한이다.
template <typename T>
class complex_t
{
T image;
T real;
public:
complex_t(int x, int y) // Constructor
{
image = x;
real = y;
}
T get_real() { return real; }
T get_image() { return image; }
};
int main()
{
complex_t<float> x( 1.0, 2.0);
complex_t<int> y( 3, 4);
//printf("%f %d\n", x.real, y.image); // Error
printf("%f %d\n", x.get_real(), y.get_image());
return 0;
}
III-2. SystemC에 대한 다른 견해
SystemC의 구문을 보면 Verilog와 상당히 닮아있다. 특히 사건에 구동되어 순차구문을 실행하는 모듈 크래스의 소속함수로 지정한 방식은 베릴로그의 always @()와 일치한다. 그외 #define 매크로를 사용하여 C++의 구문을 숨기고 새로운 언어처럼 보이게 한 부분은 억지스럽다며 베릴로그를 써도 될 것을 굳이 어렵게 C++를 도입해야 할 필요성에 의문을 가진 견해도 있다. 참고 [8]을 읽어보기 바란다. SystemC의 구성과 크래스 사용법등을 설명하면서 그 필요성에 대한 다른 견해를 표하고 있다.
IV. 맺음말
이 강좌 글을 읽는 독자는 "내 칩 MPW"에 지원하려고 반도체 설계를 배우기로 했을 것이다. 기왕 설계 방법을 익히려고 했다면 그동안 쌓아온 지식을 모두 활용해보자. 논리회로와 C 언어(C++의 경험이 있다면 큰 도움이 되겠지만)에서 시작해 보자. 만일 새로운 도구가 생소하다면 알고있는 지식을 동원하고 논리적 사고로 이해하도록 노력해보자.
반도체 설계 도구와 프로그래밍 언어는 긴 역사를 가지고 수많은 요구에 맞춰 발달해 왔다. 그런만큼 그 내용은 복잡하고 개념들은 매우 추상적이다. 이제 막 시작하는 입문자에게 방대한 개념들을 이해하기를 요구하는 것은 무리다. 다행히 도구들의 사용수준은 매우 넓다. 초보자도 기본 개념만 이해하면 충분히 활용할 수 있다. 높은 수준의 사용법은 생산성 향상을 위한 기법일 뿐이지 최종 목표의 수준을 뜻하는 것은 아니다. 종종 목적을 잊고 수단에 집착하는 경우를 본다. 컴퓨팅 언어는 디지털 반도체를 얻기 위한 수단에 불과하다.
이번 강좌는 베릴로그 HDL과 SystemC/C++를 사용한 설계 방법론에 따라 반도체 설계를 시작하기 위한 필요 최소한 수준을 제시하였다. 앞으로 연습을 통해 실전으로 설계능력을 쌓도록 하겠다. 도구 사용이 서툴다고 "반도체 설계"라는 목표를 져버리지 않길 바란다.
주] 아래 참고목록 중 Verilog[4], SystemC[3] 그리고 C++[5]의 간단 참조 문서를 인쇄하여 연습시 지참 할 것.
-----------------------------------------------------------------------
[1] Hardware Verification Language, https://en.wikipedia.org/wiki/Hardware_verification_language
[2] e Verification Language, https://en.wikipedia.org/wiki/E_(verification_language)
[3] SystemC Quick Reference card, http://www.eis.cs.tu-bs.de/klingauf/systemc/systemc_quickreference.pdf
[4] Verilog Quick Reference, https://web.stanford.edu/class/ee183/handouts_win2003/VerilogQuickRef.pdf
[5] C++ Quick Reference, https://www.hoomanb.com/cs/quickref/CppQuickRef.pdf
[6] SystemC를 이용한 시스템 설계, http://acornpub.co.kr/book/systemc
[7] SystemC와 기본 형식, https://gtrfx.github.io/2020/02/16/systemc-basics.html